前端 Monorepo 在字节跳动的实践
受邀参加第十一届 Top100 峰会,更多详情见文章年底了,看看这100位技术创新带头人如何做复盘?
分享会背景
受邀参加第十一届 Top100 峰会,更多详情见文章年底了,看看这100位技术创新带头人如何做复盘?
本主题简介

PPT 正文

- 大家早上好,我是林宜丙,今天我带来的分享主题是《前端 Monorepo 在字节跳动的实践》

- 简单介绍下我自己,我来自字节跳动的 Web Infra 部门,拥有多年前端工程化的经验,主要帮助前端工程师更好地管理和治理工程
- 目前负责前端 Monorepo 解决方案的设计及其落地工作,有丰富的 Monorepo 实践和治理经验

- 今天的分享分为以下五个部分
- 首先分析『现代前端工程开发』的趋势,并引出字节跳动,前端工程开发面临的痛点
- 其次简单介绍下 Monorepo,以及它为什么能解决我们面临的痛点
- 接着针对我们在落地过程中遇到的问题及其实践
- 再接着分享下自研的方案在字节跳动的落地情况
- 最后总结当前方案的问题和针对这些问题的展望
- OK,我们先来看看现代前端工程开发的几个趋势
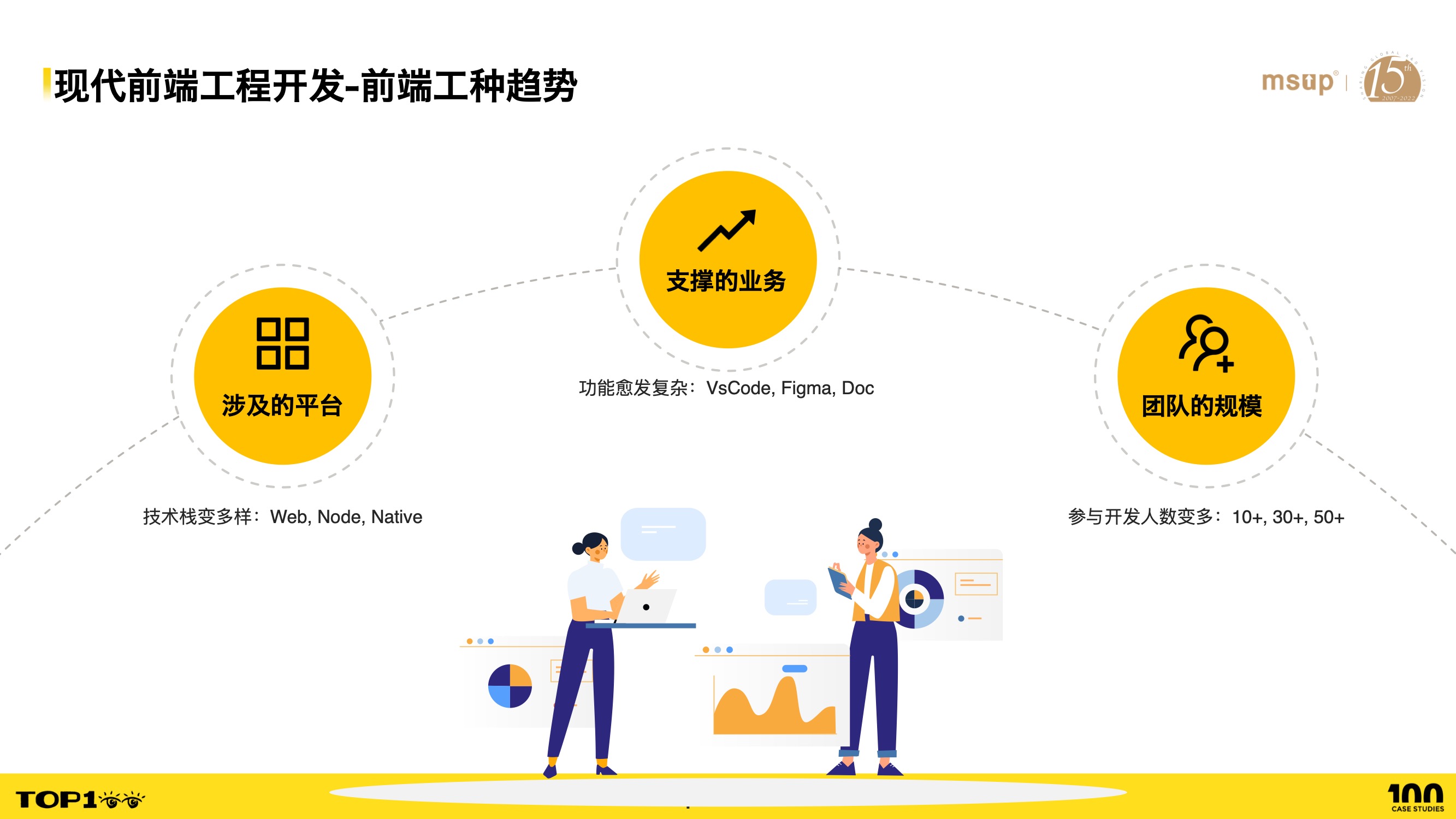
- 首先是前端工种的趋势
- 第一个趋势是涉及的平台越来越多,Web,Node,客户端和跨平台等
- 第二个趋势是所能支撑的业务越来越多,复杂度越来越大,特别是近年来前端侧涌现出不少重前端交互的应用,比如搭建类的 figma,文档类的飞书等
- 第三个趋势是随着上述两个趋势而来地、不可避免地使得前端团队的规模不断增大
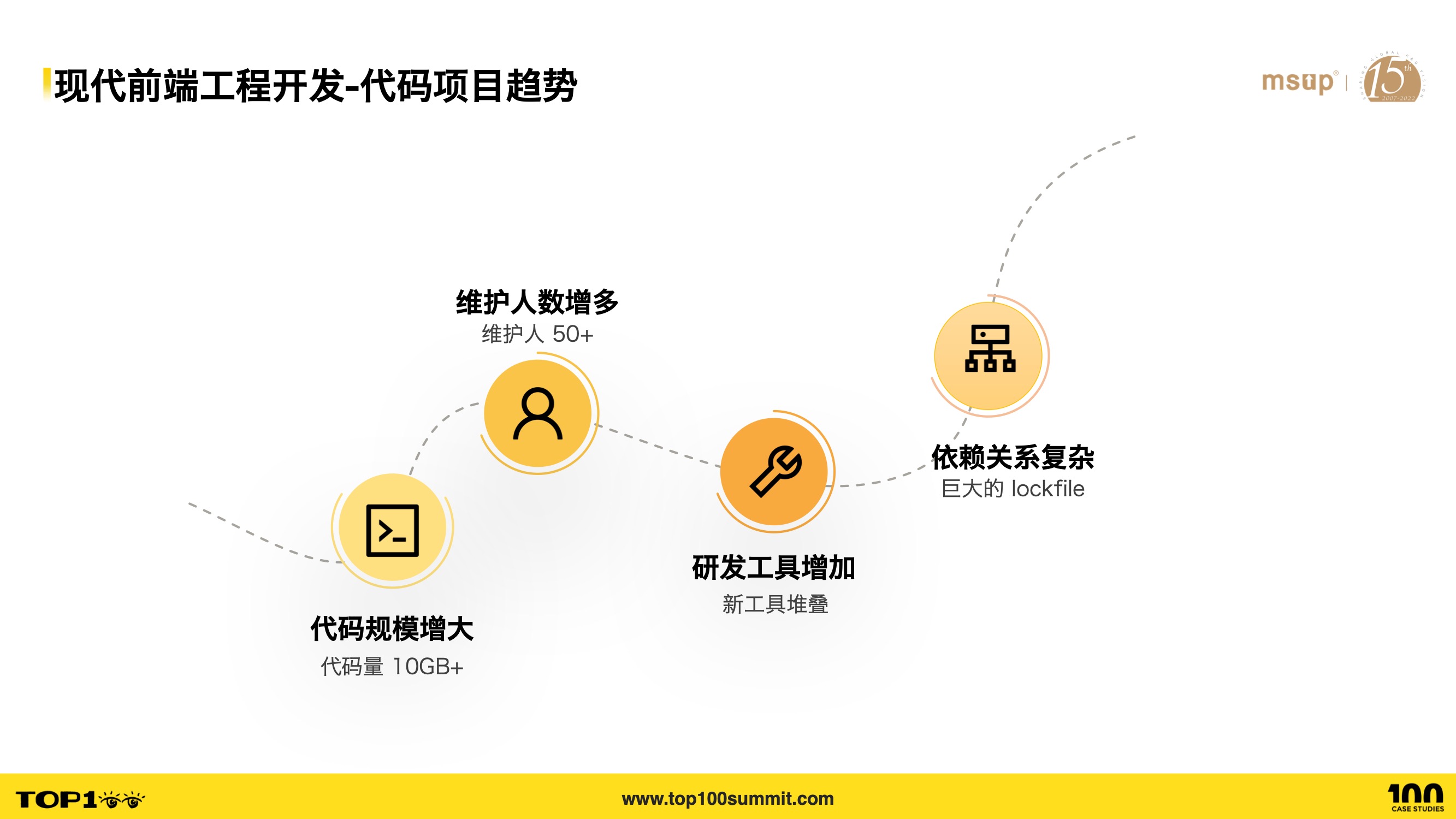
- 上述三个趋势又客观上造成了前端工程的四个趋势,即:
- 代码规模增大,内部已经出现代码量超过 10G 的大型工程
- 维护人数增多,一个工程少则十来人,多则四五十人
- 研发工具增加,不断出现的新工具在一个工程上堆叠,构建方面比如 webpack,rollup,vite 等,测试方面比如 jest,vitest 等
- 依赖关系复杂,各类项目安装依赖后的 lock 文件大小,足以说明一个工程的复杂依赖关系
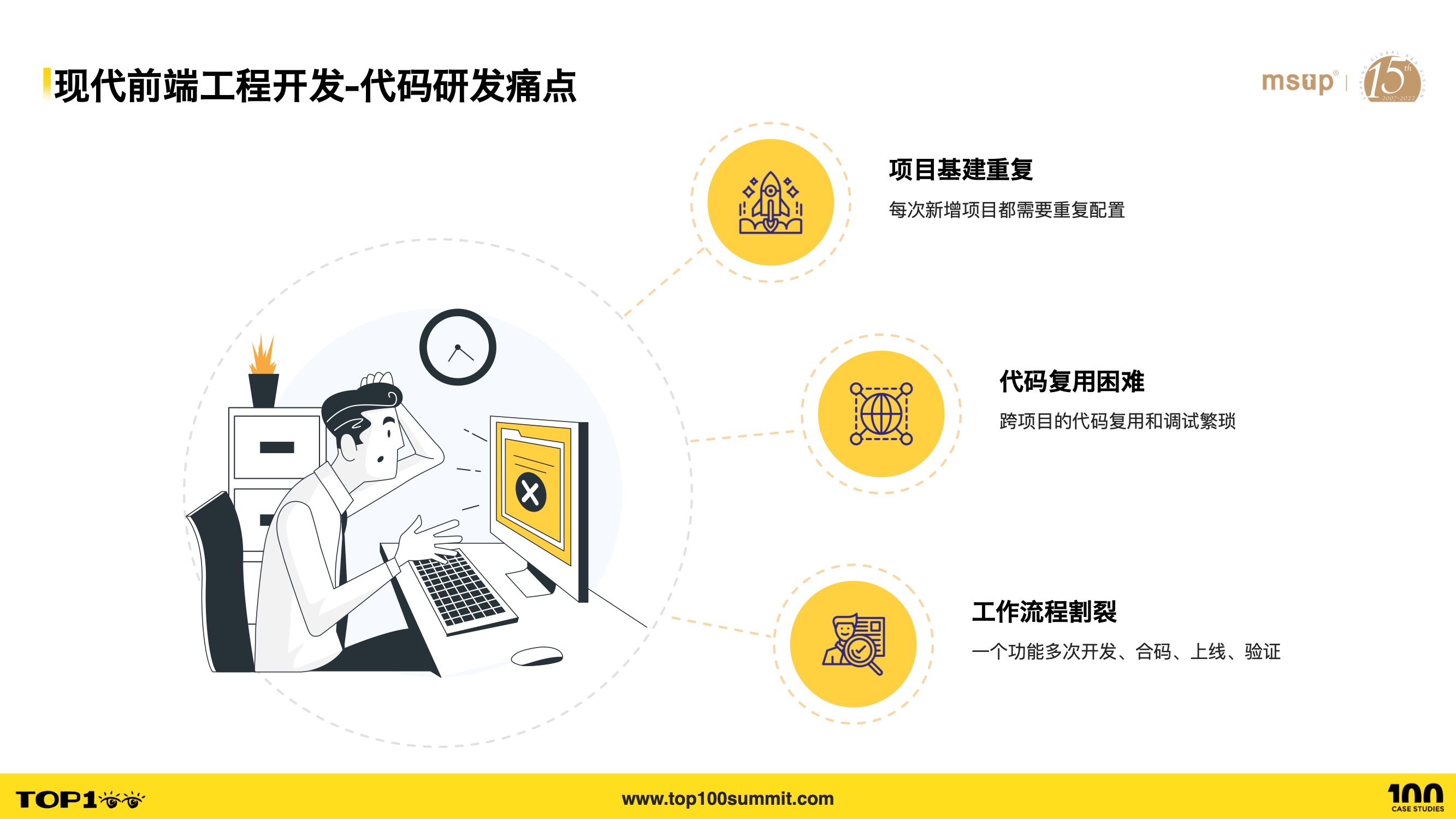
- 那么,在上述这些个趋势下,我们的前端工程开发面临了哪些痛点呢?主要有三个:
- 其一,项目基建重复,每次新增项目都需要重复配置 Git,构建平台,CI/CD 配置等
- 其二,代码复用困难,跨项目的代码复用和调试极其繁琐,往往通过发布 npm 包来复用,而这种复用方式又不可避免地遇到更新触达率的问题
- 其三,工作流程割裂,一个功能往往涉及到多个模块,这时需要分别在各个模块的工程上开发、合码、上线和验证,这是繁琐和割裂的

- 面对上述痛点,我们该如何更好地组织工程,以提高工程的『可维护性』和『开发效率』?我们给出的答案是 Monorepo!

- 接下来我们来简单介绍下 Monorepo
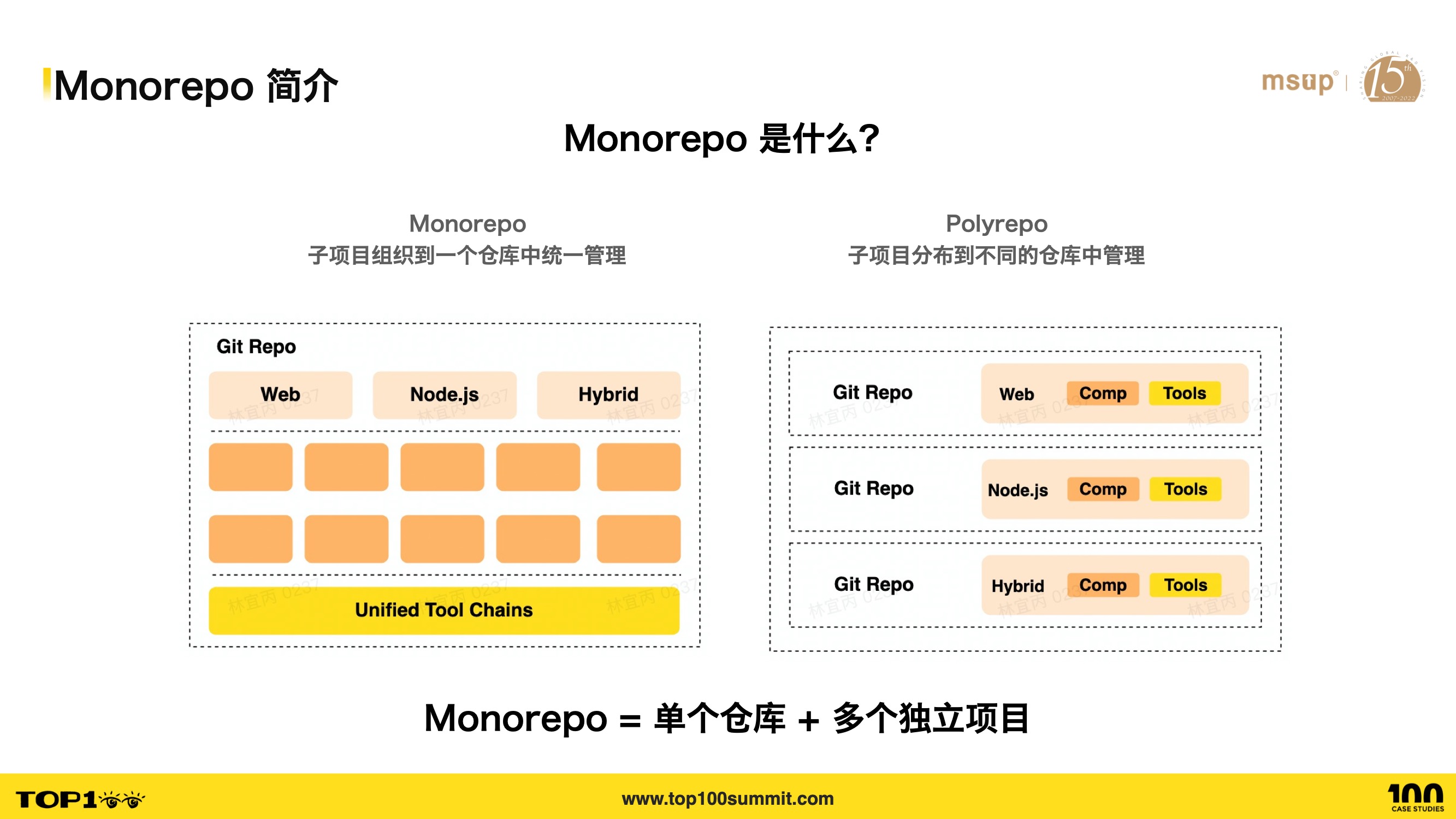
- 首先我们来看看,什么是 Monorepo 呢?Monorepo 是一种源代码管理的模式,其形式就是将多个项目集中到一个仓库中管理;
- 与 Monorepo 相对的是 Polyrepo 模式,这种模式各个项目都有独立的仓库。
- 这里需要注意,Monorepo 的子项目不仅仅是简单地放到一个仓库中维护而已,处理子项目间的关系也十分重要。
- 子项目也可以是任意的类型,可以是 web 项目,也可以是 node 项目和 Lib 库。
- 总而言之,Monorepo 就是将多个不同的项目以良好的组织关系放到单个仓库中维护。
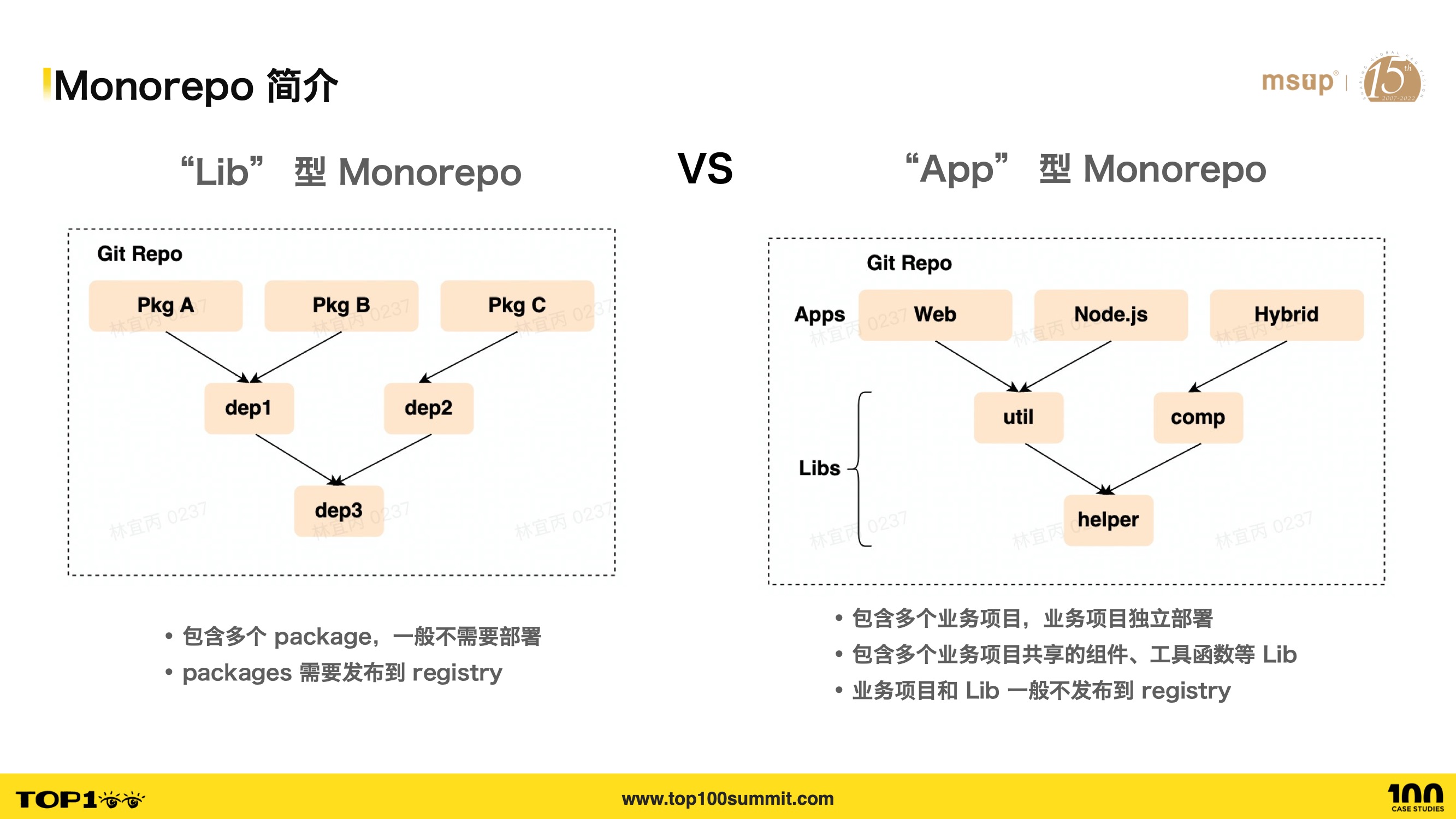
- 在前端领域,大家可能对 Lib 型的 Monorepo 更加熟悉,知名的开源项目比如 React、Vue、Babel 等都采用 Monorepo 方式管理源码,大家看左边这个图,通过将整个系统拆分成多个 package,便于抽象和复用,并且这些 package 往往不需要走线上部署流程,只需要发布到 npm registry 即可。我相信大家在公司中接触和使用到的大部分 Monorepo 项目就是这个类型,但是这类项目往往在商业公司中并不是主流。
- 除了 Lib 型以外,我们看右边这张图,多个 App 也是可以放到一个仓库中维护的,这就是 App 型的 Monorepo,它包含多个 App 项目,以及项目共享的组件、工具函数等等,App 类型的项目需要走完整的部署流程,App 及其依赖的 Lib 一般不需要发布到 npm registry,这类项目呢,才是商业公司的主流。
- 在字节跳动,大部分的项目都是 App 应用,我们侧重在这个类型上建设自研的 Monorepo 方案,它的覆盖的人群和覆盖的应用是最多的,因此它的收益也是巨大的;当然支持了 App 型的 Monorepo,自然也就支持了 Lib 型的 Monorepo。

- 那为什么要采用 Monorepo 呢?接下来我们看看使用 Monorepo 的收益都有哪些?它是如何解决我们遇到的痛点的?
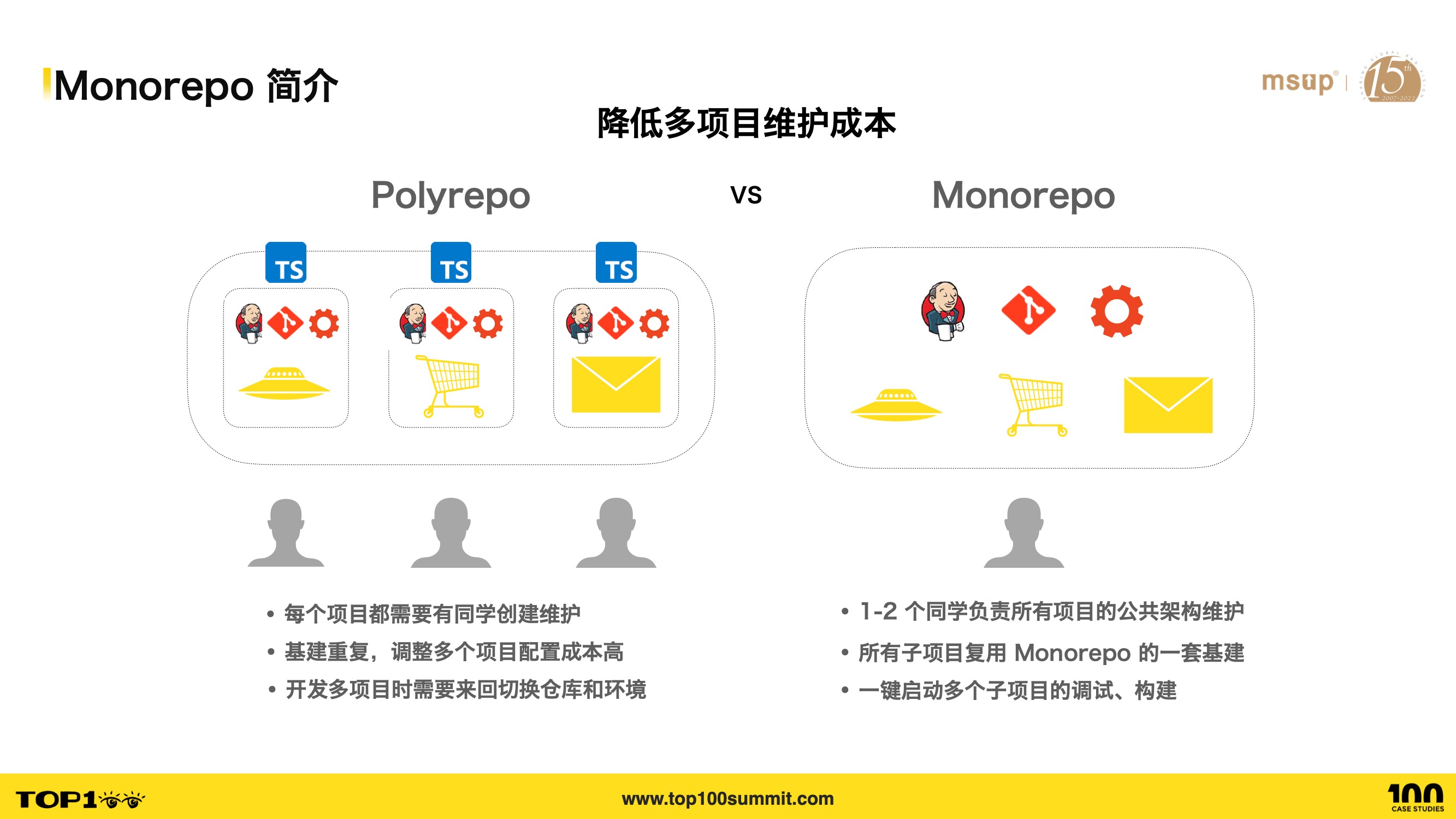
- 首先,Monorepo 可以降低多项目的维护成本,从而解决项目基建重复的痛点。
- Polyrepo 下,每个项目都需要有同学创建和维护,当创建更多项目的时候,需要更多同学,或者更多精力去创建和维护。
- 而在 Monorepo 中,只需要少数几个同学负责设立起 Monorepo,所有的项目以及将来的项目都能够在一个仓库中统一维护,从而降低多项目维护成本;
- 此外,Polyrepo 下,多个项目的基建有很多重复,当团队有多个项目的时候,需要频繁创建 git 仓库,配置 CI、Lint 规则、构建等等,而且为每个项目创建的基建后续都需要有人来维护。
- 同时将一个项目的调整,同步到其他项目的成本也很高,比如想在 CI 流程中为所有项目加入类型检查,来提高下 ts 项目的质量,那么需要修改每个项目,提交代码,跑 CI,这样成本其实是很高的。而在 Monorepo,只需要创建一套基建,所有子项目,以及未来的子项目都能够接入现有的基建。这些基建的调整和维护,也能够很容易地应用到多个项目。
- 在 Polyrepo 中,如果要开发多个项目的话,还可能需要来回切换开发环境、切换仓库,link 代码,而在 Monorepo 中可以一键启动多个子项目的调试、构建,从而提高研发效率。
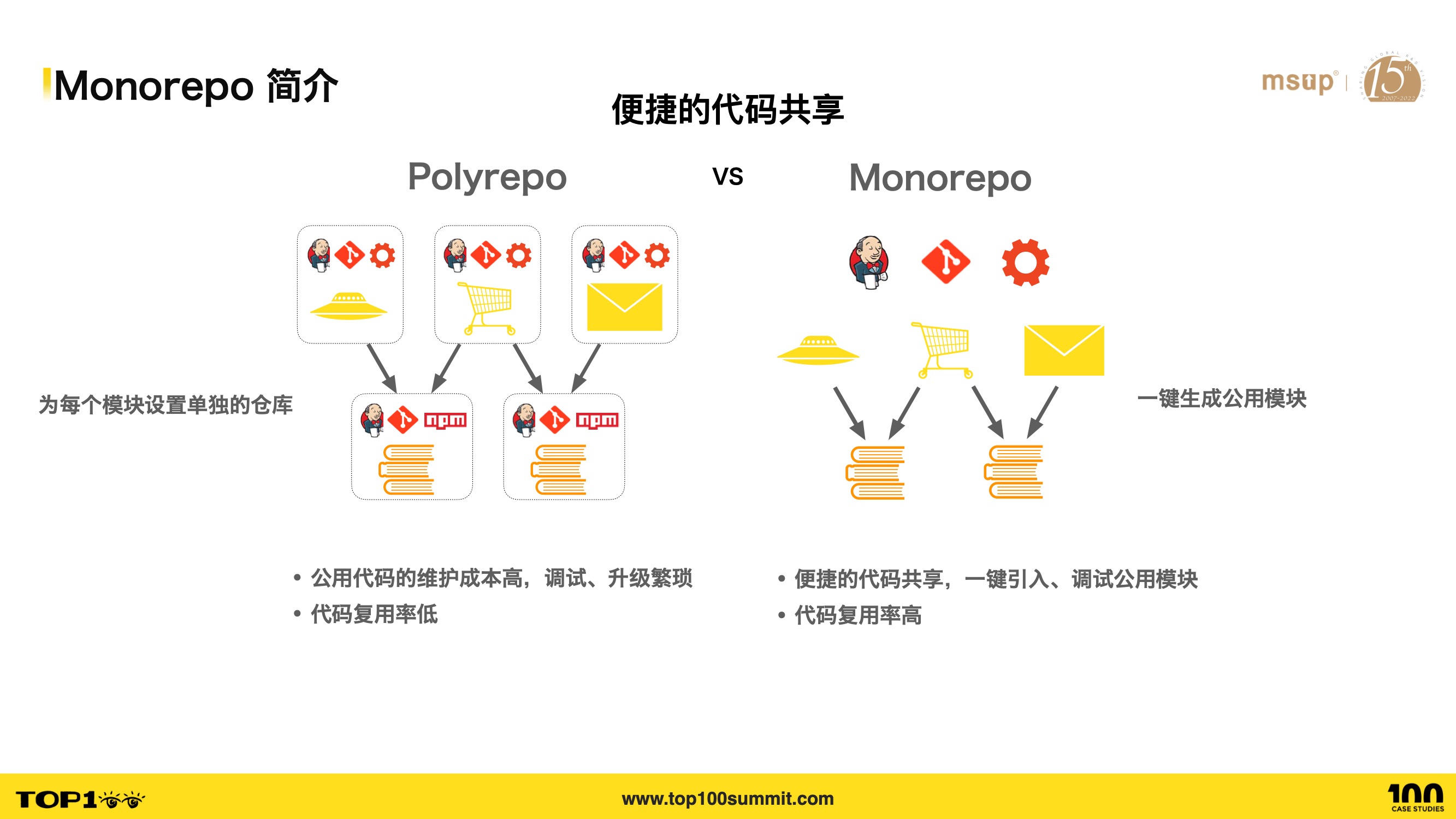
- 其次,在 Monorepo 下可以很方便的共享代码,从而解决代码复用困难的痛点。
- Polyrepo 中,复用公用代码比较困难,需要为公用代码单独维护一个仓库,此外升级、调试流程也十分繁琐低效。
- 首先是调试很繁琐,公用模块的调试需要手动执行 link,与当前调试的项目关联起来,如果公用模块较多的话,link 步骤将非常繁琐低效。
- 其次公用模块的升级很繁琐,需要手动管理这种依赖关系,先升级底层的模块,然后发布,最后再升级顶层模块,如果升级完之后发现有问题,这些步骤还得重来一次。此外,推动上层模块更新也不能及时触达。
- 而在 Monorepo 中,可以直接一键创建公用模块,顶层的模块一键引入公用模块进行开发、调试,底层模块的更改能够直接被上层感知,甚至不需要经过 link 和 npm 发布,即可在本地调试或者部署平台发布,降低了很多重复的工作。
- 因此,在 Polyrepo 中复用代码比较困难,导致代码复用率比较低,而 Monorepo 中能够很方便的复用代码,抽离新的工具库的成本非常低,这使得大家更愿意做这类抽离工作,提高了代码复用率。
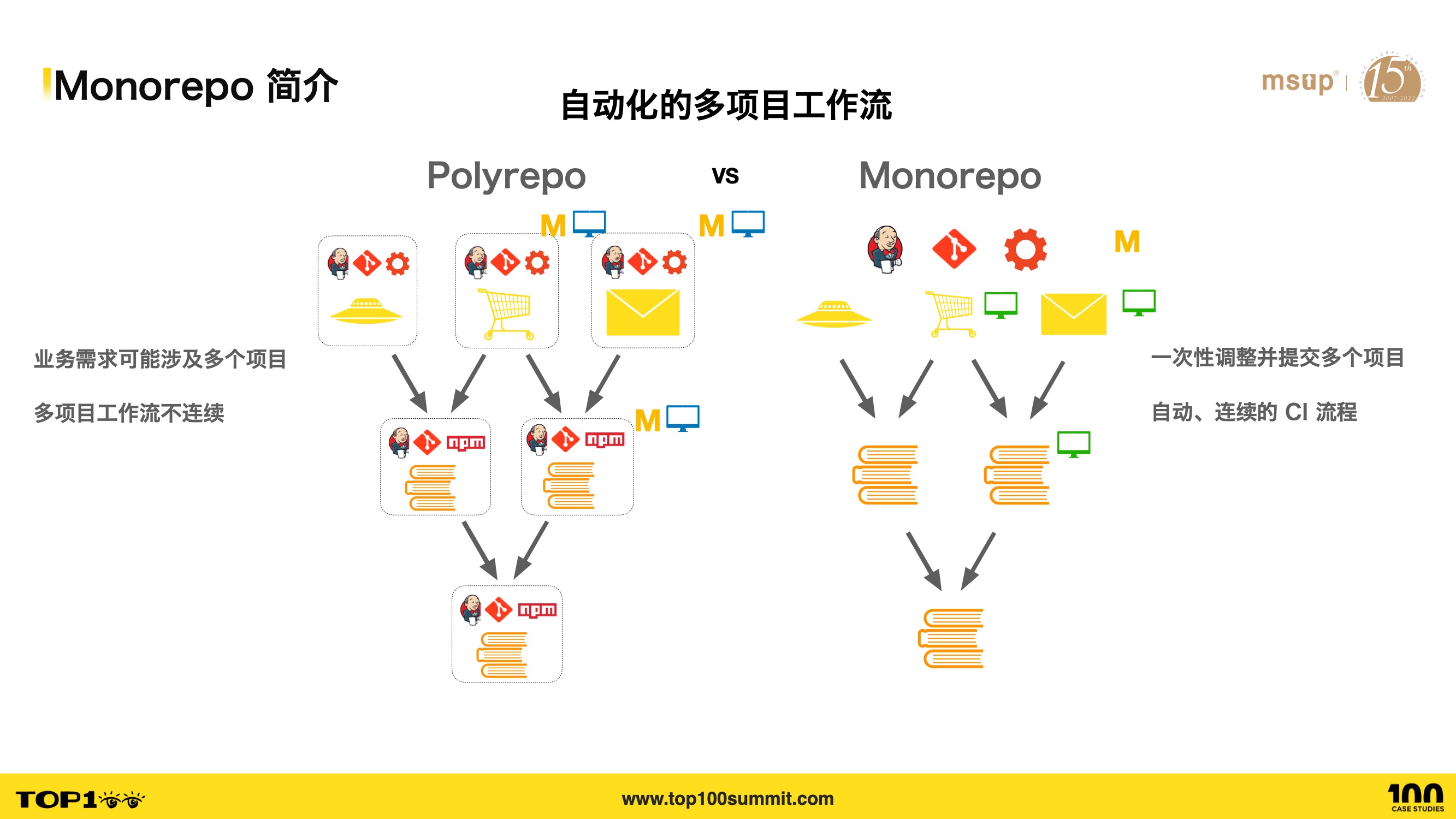
- 再次,在 Monorepo 里能够实现自动化的多项目工作流,从而解决工作流程割裂的痛点。
- 如果我的业务需求要涉及到多个项目,在 Polyrepo 模式中,我需要修改多个项目,对多个项目各自提交 commit,每个项目单独跑 CI 流程,如果项目间有依赖关系的话,还需要手动升级项目的依赖版本。例如需要修改图中的三个项目,需要先修改提交底层模块,跑每个模块的 CI 流程,在处理顶层模块时,还得更新底层依赖,接着再跑一次 CI 流程,这一套流程非常繁琐且不连续。
- 而在 Monorpeo 中,我们可以直接修改多个子项目,只需一次 commit 提交,多个子项目的 CI 和发布流程也是一次性的。从而将整个多项目的工作流自动化,连续化。
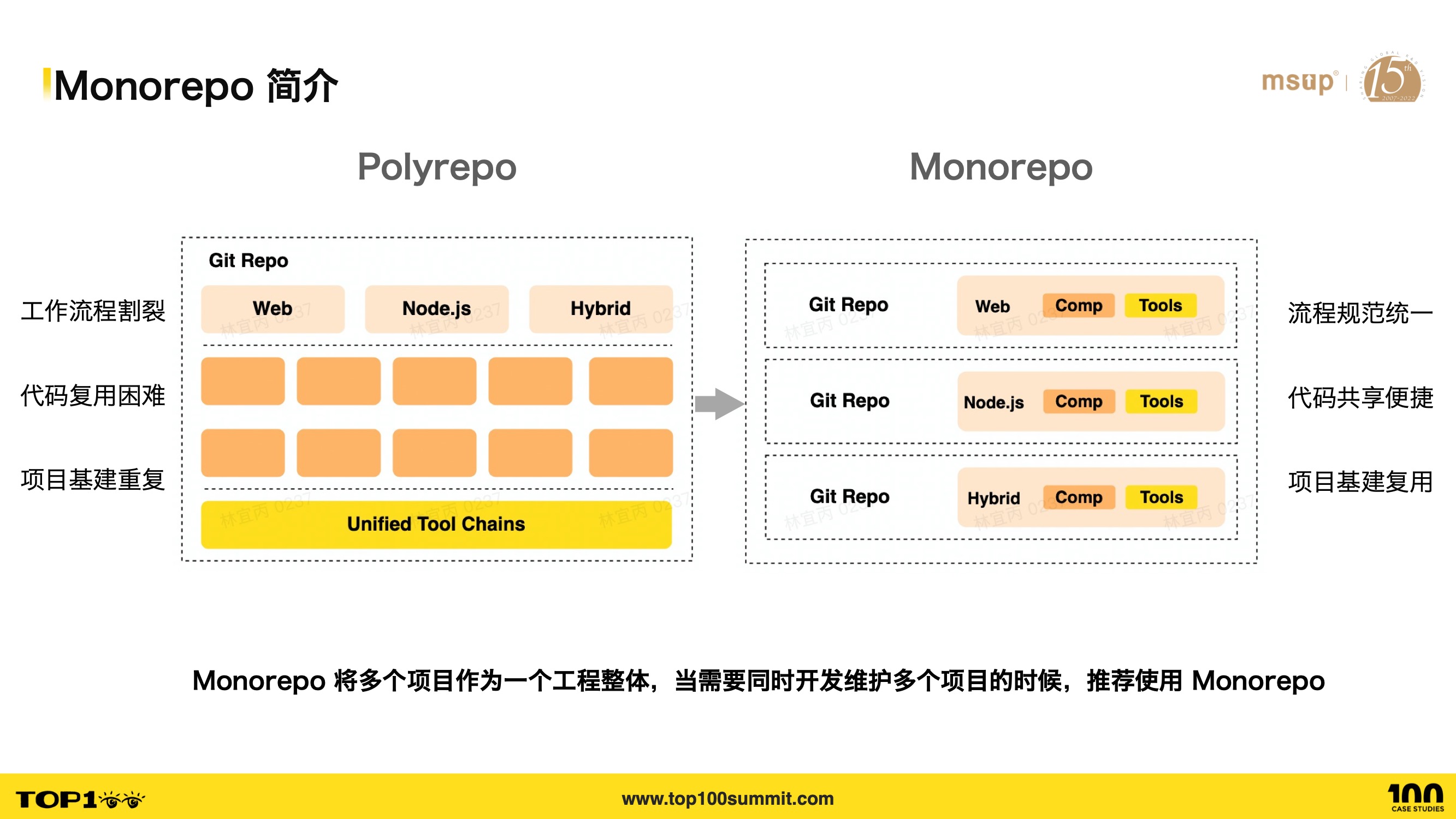
- 我们简单的做一个总结:在 Polyrepo 的模式下,每一个项目都有自己的地址、仓库,这会导致共享代码很困难,基建比较重复,同时工作流也比较割裂。
- 但是在 Monorepo 里面,我们可以将多个项目的工作流进行规范统一。比如说统一的 CI 流程、 code review 等等。同时,它的代码共享也比较方便,我们可以直接将多个项目共享的组件或者工具函数,抽离出来,便可以在多个项目间复用,当然,多个项目的基建也可以复用。
- 很多时候一个团队、或者一块业务,他们的项目之间并不是完全割裂的,而是相互联系的,Monorepo 可以很方便的将这些项目组织到一起,进行维护。当团队有多项目需求的时候,推荐使用 Monorepo。
- 当然,Monorepo 并不是银弹,Polyrepo 也能符合大部分的场景,我们选择 Monorepo 是基于我们遇到的痛点考虑和权衡的,使用 Monorepo 虽然很好地解决我们遇到的痛点,但是也给我们来了不少额外成本,接下来的部分我会着重分享,在采用 Monorepo 方案后,所带来的问题及其实践。

- 接下来,我们来看看引入 Monorepo 方案后遇到的问题,以及我们在解决这些问题方面的实践
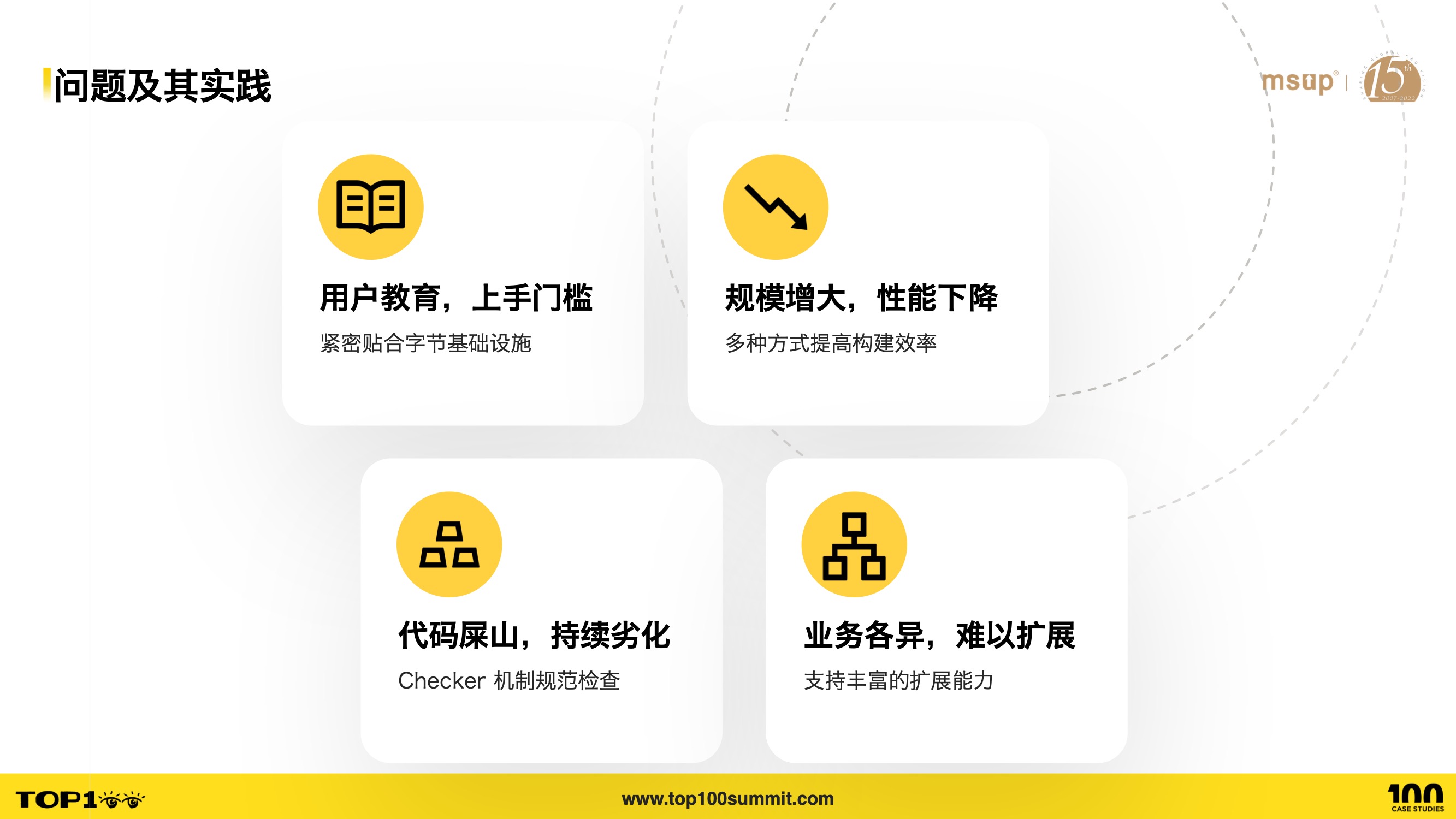
- 我们的自研方案在实践过程中,主要遇到如下四个方面的问题:
- 第一个,因为大部分用户习惯于 Polyrepo 的开发,有些甚至是第一次使用 Monorepo,因此存在用户教育,上手门槛的问题
- 第二个是随着业务的迭代,Monorepo 工程的规模,即子应用数量迅速增多,而一次调试和构建往往涉及多个子应用,从而导致调试、构建性能下降
- 第三个是 Monorepo 工程的生命周期往往比 Ployrepo 长很多,且参与开发的同学也非常多,如何确保合入工程的代码保持良好的可维护性,也是一个挑战
- 第四个,字节的业务线众多,号称 App 工厂,那么面对这些不同业务的需求,如何提供丰富的扩展能力呢?
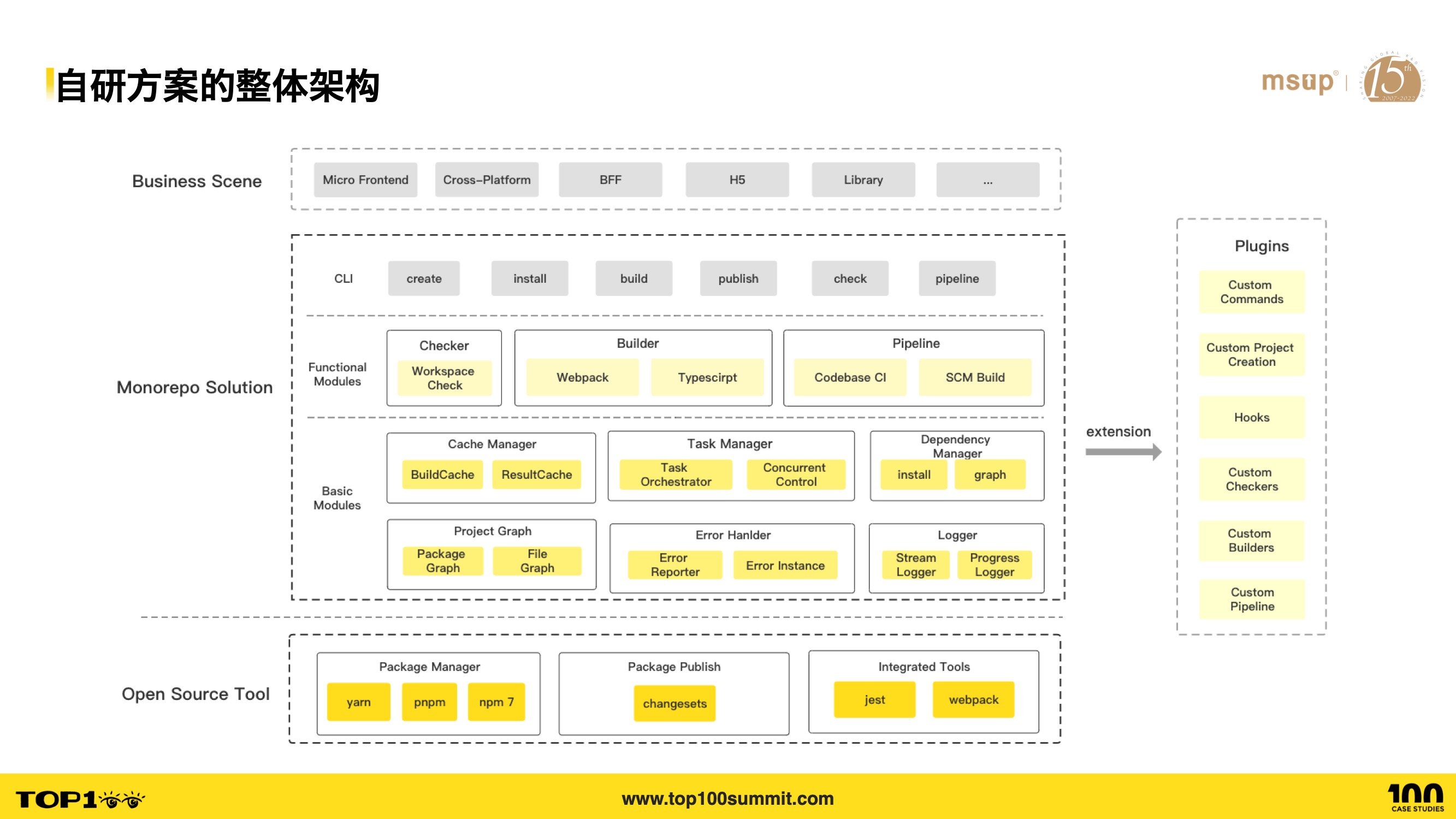
- 此处简述我们自研方案的整体架构,主要分为三层,底层是开源工具层,即我们依赖的开源方案,有 npm 包管理器,changesets 版本管理工具,子应用集成工具,比如 jest 和 webpack 等;
- 顶层是各类业务场景的支撑,有微前端、跨端、BFF、H5、Library 等场景;
- 中间层是自研的解决方案,方案也包含三个层次,底层是各类基础能力的封装,比如缓存管理、任务管理、依赖管理、子项目管理等;中间是面向用户的功能模块封装,比如 Checker、Builder、Pipeline 等;顶层则是命令行工具,提供各种命令用于调用 Monorepo 的能力;
- 右侧则是自研方案提供的,基于插件的扩展能力。
- 架构设计不是本次分享的重点,接下来才是我们的重点,重点分享这套自研方案,在面对上述四个问题时,它是如何实践的。

- 因为相当多的用户对 Monorepo 项目的开发方式了解不足,习惯于 Polyrepo 的开发,甚至此前都没有接触过 Monorepo 项目的开发。
- 因此在加强用户教育,降低上手门槛方面,我们紧密贴合字节基础设施,实践有
- 提供『内置脚手架』工具,使得用户能够一键创建字节常见的应用类型
- 提供『CI/CD 能力』,适配字节基建的发包和构建流水线
- 提供『可视化扩展』,通过界面教育和引导用户使用
- 接下来我们展开说说
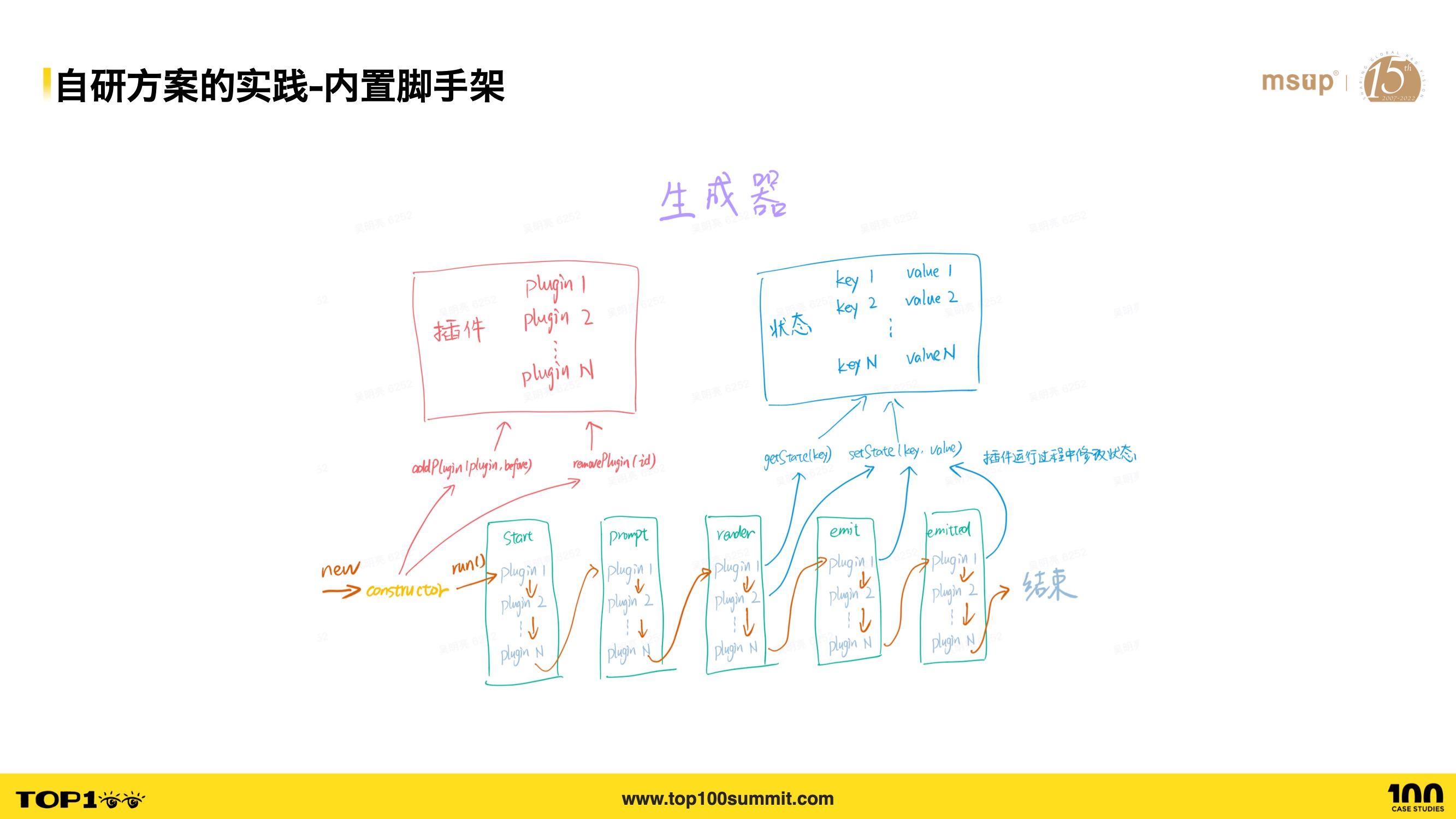
- 内置脚手架方面,我们提供了一种生成器的模版机制来应对子项目的初始化,我们集成字节常见应用类型的模版(Lynx、Gulu、Garfish、组件库/工具库等),此外也能实现自己的模版,模版既可以是项目级别的,也可以是组件级别的。
- 如图就是生成器的架构图,它由 5 个 stage 组成,比如 prompt 阶段用于收集用户的命令行输入,render 阶段是渲染模版文件阶段,emit 阶段是生成模版文件,然后通过插件机制,使得每个插件能够在上述 5 个 stage 中处理插件的逻辑,我们提供的插件有 Git 仓库创建插件、SCM 创建插件、Npm 依赖安装插件等。
- 基于生成器的设计,用户能够定制合适自己业务线的、开箱即用的模版,一键创建项目及其 Git 仓库、配置 SCM 构建等,降低了创建项目的成本。
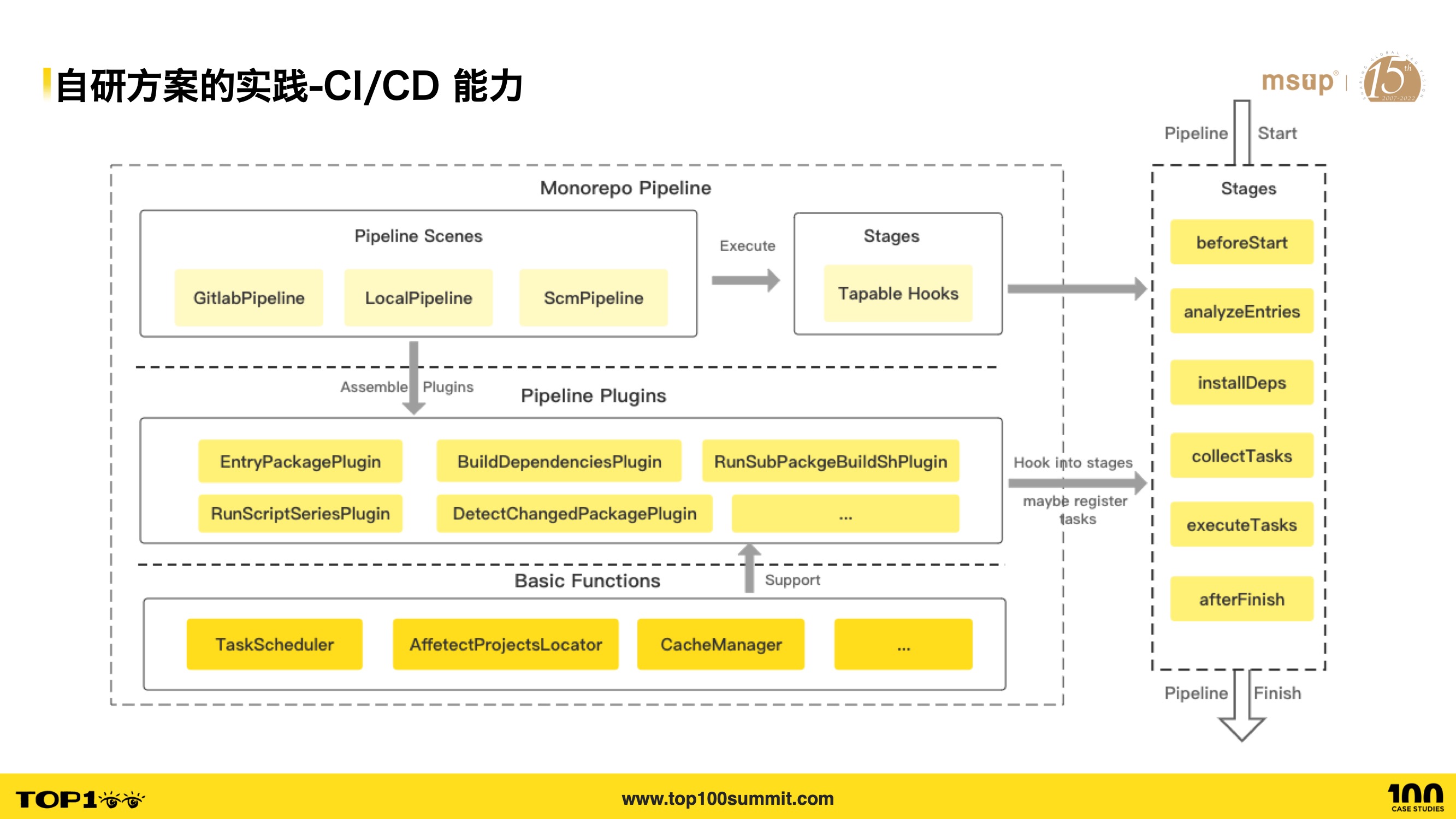
- 接下来看看 CI/CD 能力方面的实践,如下是架构图,它也是通过插件的机制来实现的,比如 EntryPackagePlugin 用于入口应用探测,BuildDependenciesPlugin 用于构建依赖,RunSubPackageBuildShPlugin 用于执行子应用的 shell 脚本;
- 为了实现多环境支持,它会对每一种场景都有对应的 Pipeline,比如 GitlabPipeline 和 SCMPipeline,可以简单的理解为,为每个场景维护了一份插件集合,然后在对应的场景执行时会调用对应场景的 Pipeline,每个 Pipeline 都会执行相同的 stage;
- stage 列表如右边所示,其中 analyzeEntries stage 会分析依赖,得出哪些代码变更了,collect tasks stage 会去调度子项目的任务流水线。
- 基于插件集的定制,使得当前的 Pipeline 机制在 SCM 和 Gitlab CI 场景下开箱即用,也方便为未来新的场景进行扩展。
- 这套机制支持了 Gitlab CI 自动发版流水线与 SCM 构建流水线等场景,大大降低了应用接入发版平台和构建平台的成本。
- 可视化扩展方面,我们通过界面教育和引导用户,提供快捷操作创建子应用、调用各类命令、搜索子应用、配置 Monorepo 等;
- 从而降低新手用户的上手成本、降低记住命令的心智负担。

- 因为 Monorepo 势必会让子应用迅速增多,而一次调试和构建往往涉及多个子应用,从而导致调试、构建性能下降,所以我们需要有特别的方案来保障调试和构建的性能。
- 因此在规模增大导致性能下降方面,我们通过多种方式提高构建效率,实践有
- 支持『任务并行能力』,采用最大限度的批量任务并行加速
- 支持『多级缓存能力』,对依赖安装、构建产物、测试结果等实现了多级缓存
- 支持『按需构建能力』,根据依赖图和代码更改的影响面来构建和测试
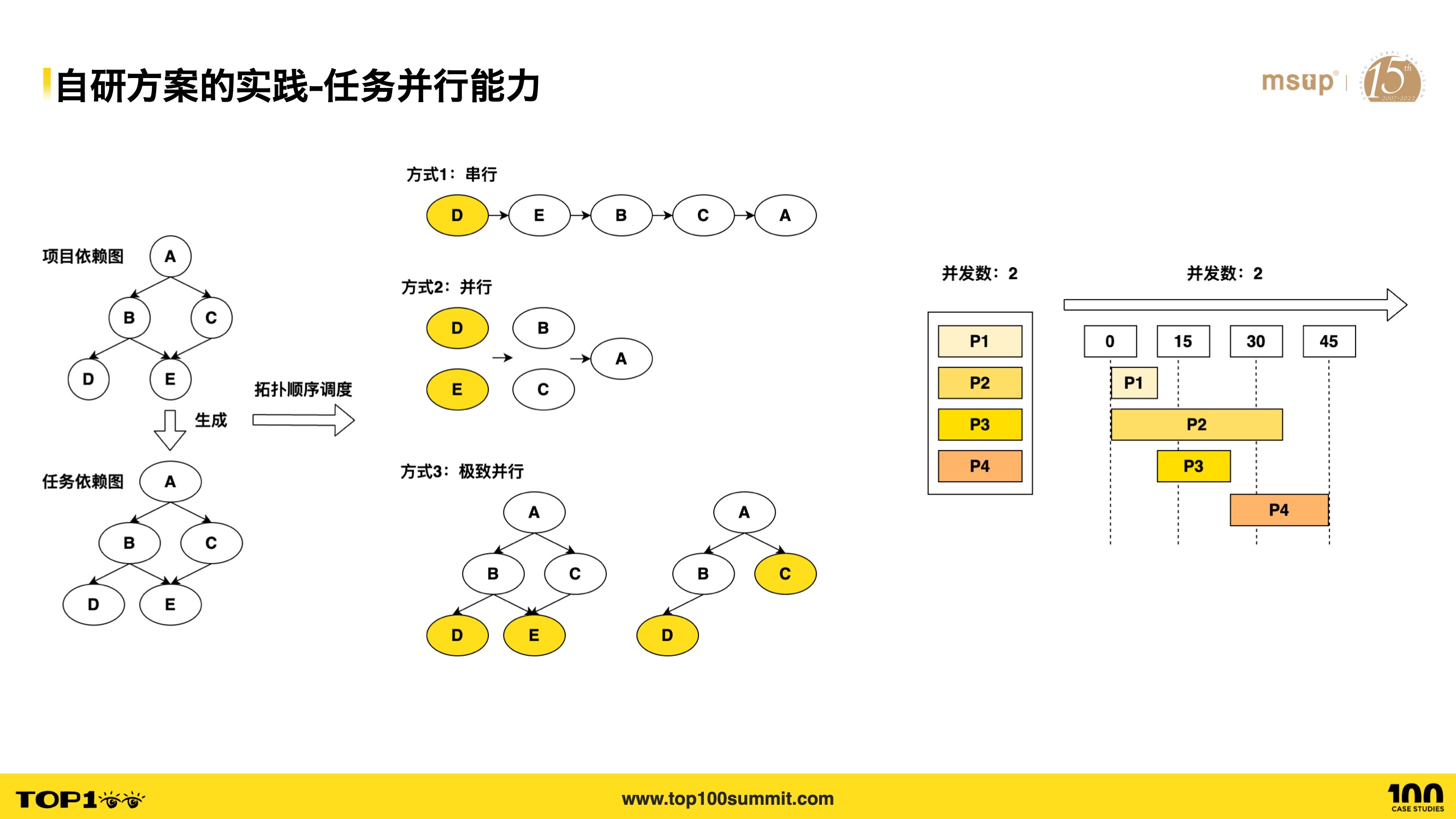
- 接下来看看我们是如何实践任务并行能力的!
- 如图所示,根据子项目的依赖关系转成一个任务依赖图,就可以根据这个依赖图进行任务的调度。
- 看左下角的任务依赖图,它的构建顺序必须符合这样一种要求,即上层的项目构建依赖于底层项目构建的完成。
- OK,我们看方式一,一种最朴素的方式,即通过串行排成 DEBCA,这是能够符合构建要求的;但是它的性能是比较低的,比如 D 和 E 是可以并行的,所以第二种方式就是通过把 DE 以及 BC 进行并行处理,这样便能把前面的 5 个步骤加速到 3 个步骤。但这种优化还不够极致,我们发现任务 C 呢,不依赖任务 E 的完成,但是方式二下,任务 C 却得等待 D 和 E 都完成才开始执行。
- 因此便引出第三种方式,在任务 E 完成后,D 和 C 便可以并行执行;考虑到并行执行涉及的子项目任务过多时,会导致 cpu 过载,因此还配套了并发控制能力,比如右侧的时序图,4 个需要执行的任务,最大的并发数为 2。
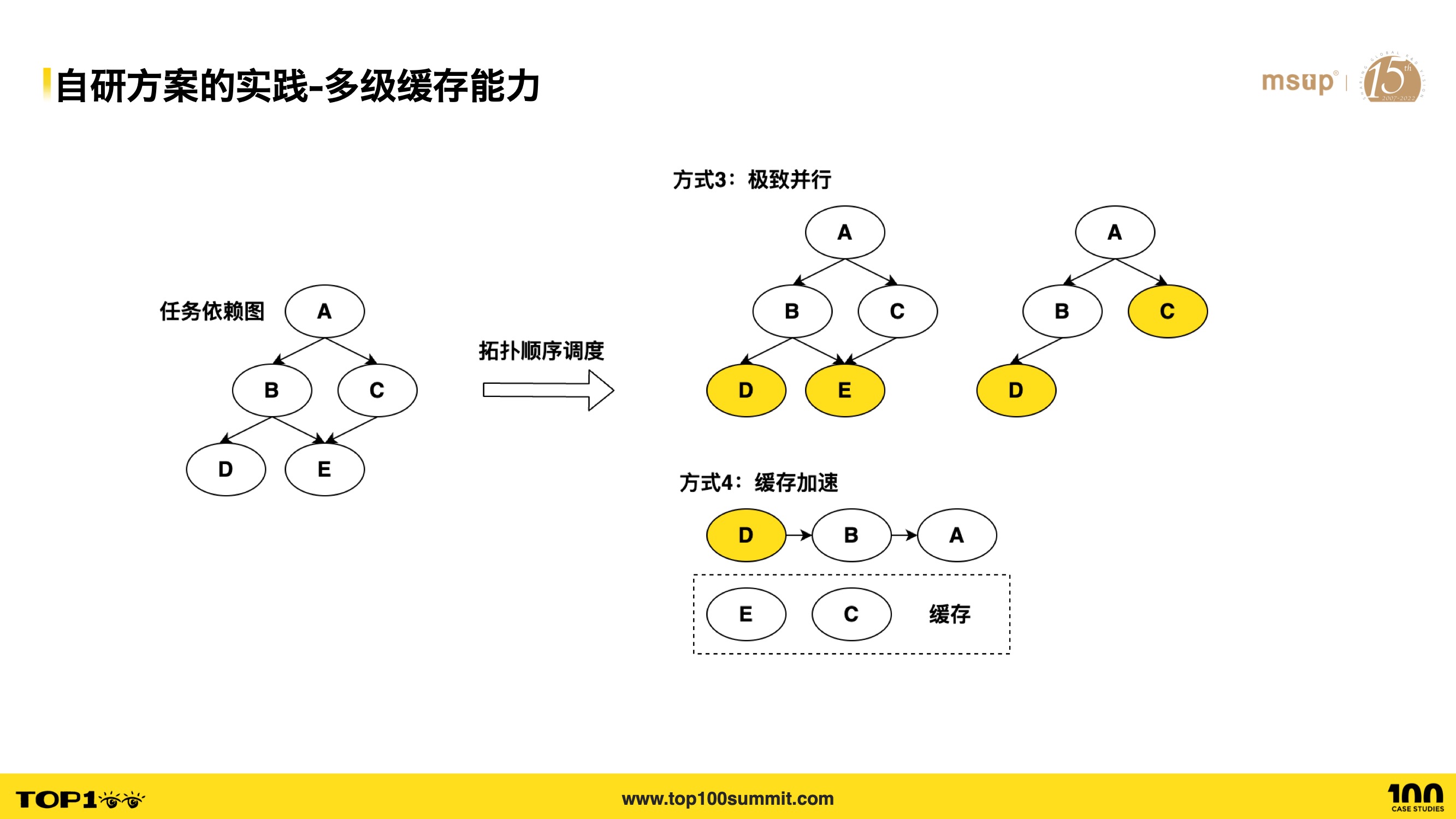
- 接下来看看多级缓存能力的实践,当 monorepo 体积增大以后,每一次开发或者上线都可能涉及到数个子项目,每次都需要对这些子应用进行重新构建,这将会极大地拖慢构建和部署时间。
- 我们提供了对构建产物进行缓存的能力,能够同时将产物缓存到本地和远程,当相关的子项目没有修改过代码时,将会复用之前的构建产物以减少构建时间。此外,除了构建任务,其它的操作,比如单测任务的执行,也会缓存结果,从而跳过单测任务。
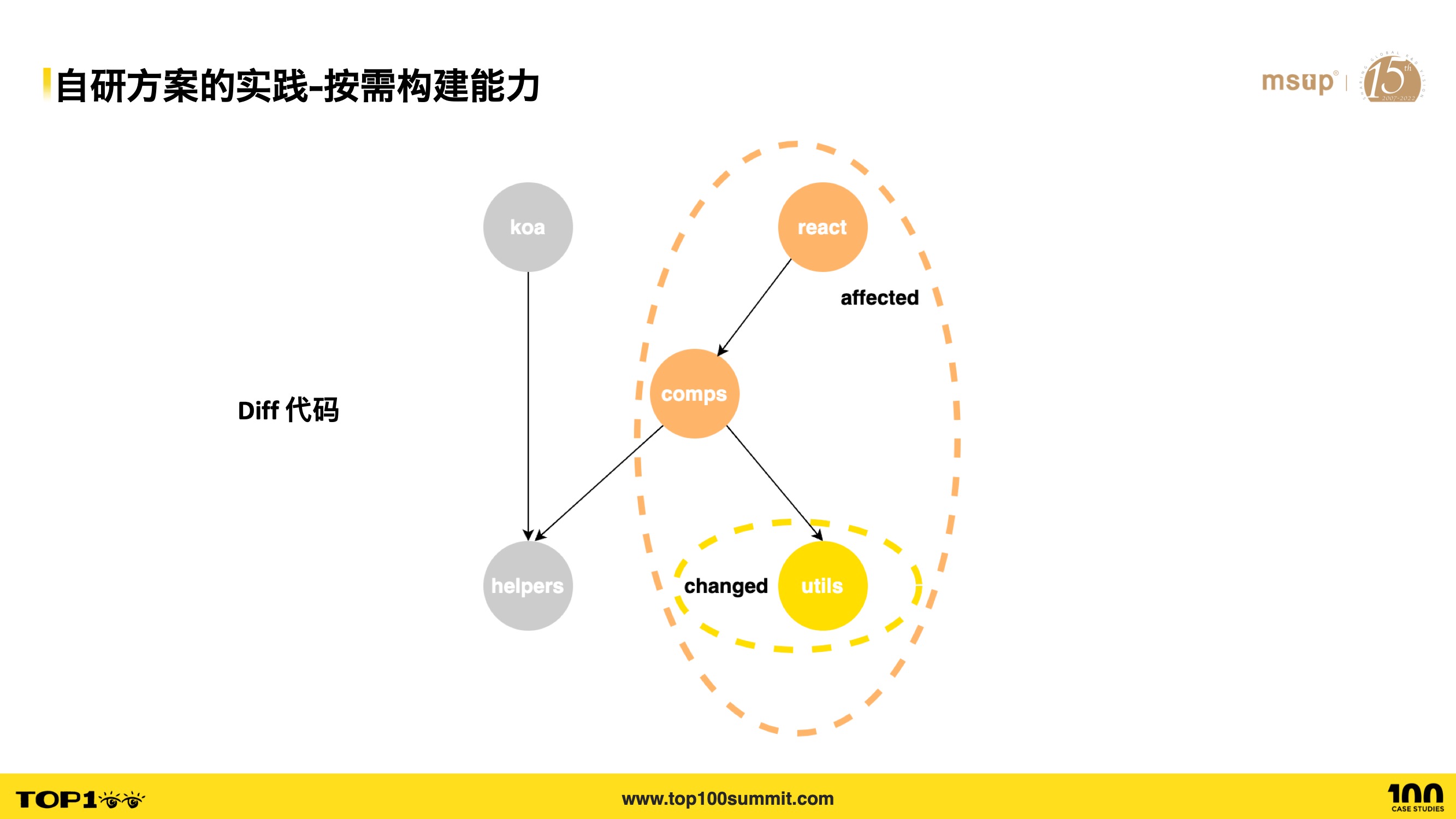
- 按需构建能力方面的实践,我们支持按影响面执行 CI 流程,通过 diff 更改的代码并进行依赖分析,得到整个 Monorepo 中受影响的项目,并执行其 CI 流水线;否则每次 CI 都会完整的构建整个所有的子项目
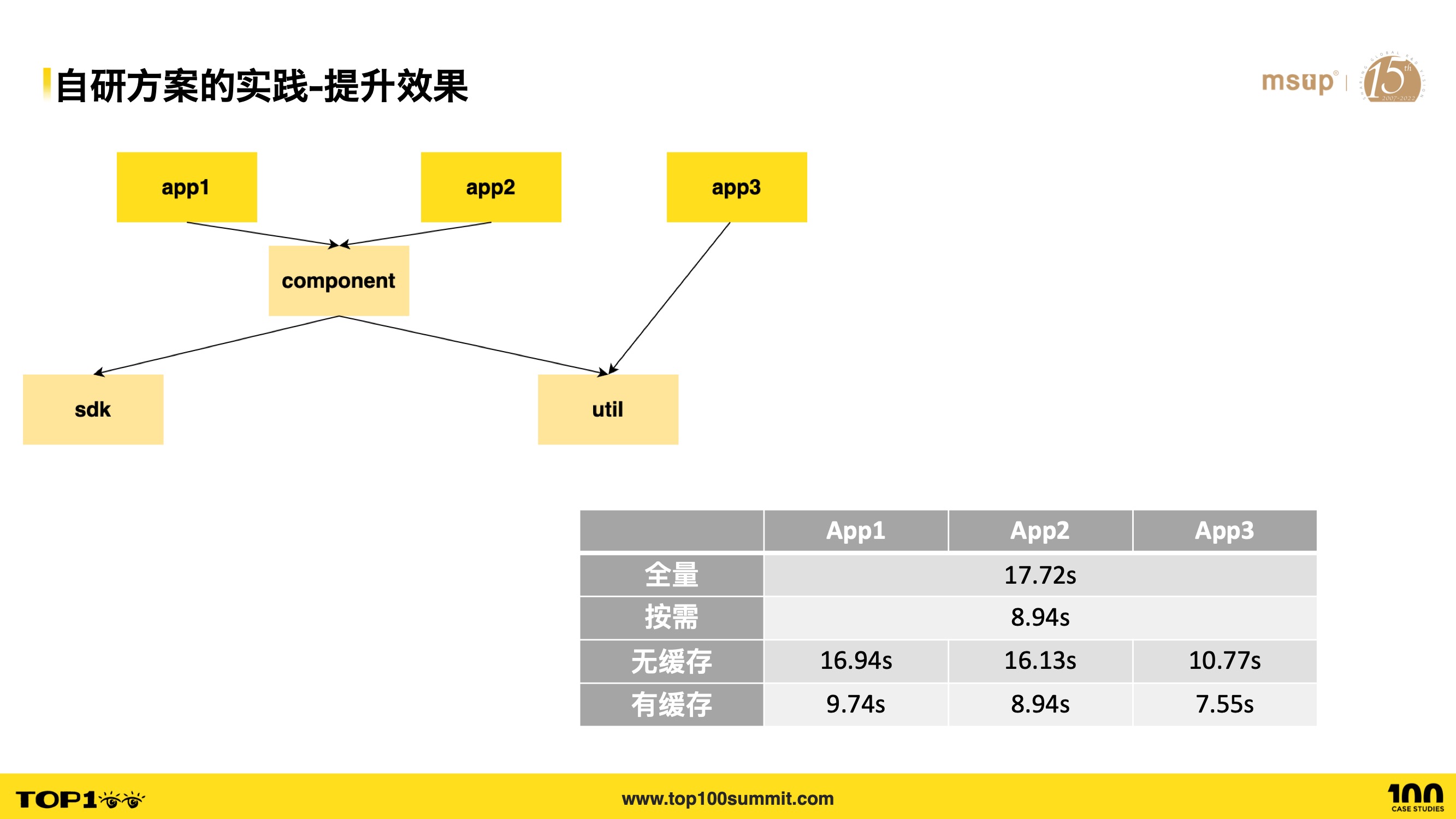
- 此处以一个简单的 Monorepo 为例,依赖关系如图所示,三个 App,一个 Component,一个 Sdk 和工具库
- 如果一次性全量构建所有应用,耗时约为 17.72秒
- 如果仅仅改动了 component 模块,那么按需构建的话,我只需要构建 component, app1, app2,此时耗时 8.94秒,节约 50% 的时间
- 再来看看无缓存的情况下,我仅仅构建 App1, App2, App3 它们的耗时在 10.77秒到16.94秒之间
- 如果有缓存的话,比如 component, sdk, util 已经构建过,那么再单独构建 App1, App2, App3 时,构建耗时在 7.55秒到9.74秒 之间,大约节约 45% 的时间

- 因为 Monorepo 会让众多水平不一工程师在同一个仓库里开发,而且仓库每周新增的代码量都是巨大的,所以我们更需要去保障代码质量。
- 因此在代码防劣化方面,我们通过 Checker 机制进行各类规范的检查,实践有
- 支持『内置多种 Checker』,确保项目基本的可维护性
- 支持『自定义 Checker』,使用户能够编写基于各自团队的规范检查
- 支持『支持自动修复』,自动修复不符合规范的代码或配置

- 我们内置了多种 Checker,用于保证基本的可维护性,比如统一依赖版本,它会检查各项目的 package.json 下相同依赖版本是否一致等等
- 此处以统一依赖版本一致为例,我们都知道,如果多个项目使用相同依赖的不同版本容易导致问题,比如 components 和 app 的 react 版本不一致,就会有 react hooks 报错等问题,此时应用这里的第一个 Checker,就能检测这个问题,并自动修复为统一的版本。

- 如果内置的 Checker 不满足用户对于规范的需求呢?我们也提供了自定义 Checker 的能力,在每个 Checker 内部,我们注入当前 Monorepo 工程的配置和依赖图等上下文信息,Checker 开发者便能通过这些信息去 check 当前的工程是否符合规范。

- 当我们探测出问题后,其实有些不规范是能通过自动修复解决的,就像 eslint 一样,我们也支持自动修复代码

- 因为字节的业务线众多,号称 App 工厂,所以各个业务对 Monorepo 有这样或那样的扩展需求。
- 因此在面对这些不同业务的扩展需求方面,我们通过插件机制支持用户自定义命令,Checker,生成器,并暴露整个生命周期的钩子,以提供更灵活的扩展能力

- 以上就是自研方案在实践过程中遇到的一些问题,接下来简要说说整体的落地情况

- 在字节前端领域,我们的自研方案在所有的 Monorepo 工程中
- 仓库占比达 25%,采用自研方案的仓库绝对数量已经有上千个
- 月活占比 47%,拍平后的子应用总数接近多仓项目数量
- 每周的 npm 包下载量达 14万+
- 在字节跳动的前端领域,无论从仓库占比,月活占比,以及下载量来看,我们的自研方案都是排名第一的 Monorepo 工具


- 过去通过自研方案的建设,拥有高效率、可扩展、开箱即用的 Monorepo 解决方案,良好地服务了字节跳动上千个 Monorepo 工程,颇受业务好评。当前的 Monorepo 方案,面临几个核心问题:
- 第一个,本地任务调度性能瓶颈,巨型 Monorepo 仓库开始出现依赖安装和构建速度问题,需要更极致的性能和体验优化
- 第二个,缺乏缓存管理能力,如何跟踪和解决缓存命中率偏低问题
- 第三个,依赖可读性问题,目前文本形式的依赖结构难以理解,这也导致难以对依赖进行有效的管理
- 我们对上述问题的解决方法如下:
- 针对性能,我们将会自研依赖安装逻辑,加速安装;任务调度性能加强(比如子项目任务调度能力,远程任务执行能力),加速构建
- 针对缓存,我们将会开发缓存 sdk,提供缓存的管理和复用能力,跟踪和提高缓存命中率
- 针对依赖管理,我们将提供开发辅助工具,用可视化的方式管理复杂的依赖关系

PPT 附件
前端 Monorepo 在字节跳动的实践

