Midscene 的一次 aiAct 里到底发生了什么?
上一篇《为什么 Midscene 的 UI Agent 非得看见屏幕?》讲了 Midscene 为什么把”看截图”放在 UI 操作的最前面。但讲完那个判断之后,我经常被同事问下一个问题:
“那
aiAct内部到底跑了什么?我写一行agent.aiAct('登录后下单'),代码里发生了什么?是一次模型调用吗?”
不是一次。是一个带反馈的循环。
这篇想把这个循环拆开讲一遍:截图怎么拿、AI 返回的是什么、循环什么时候停、多轮之间怎么传上下文。
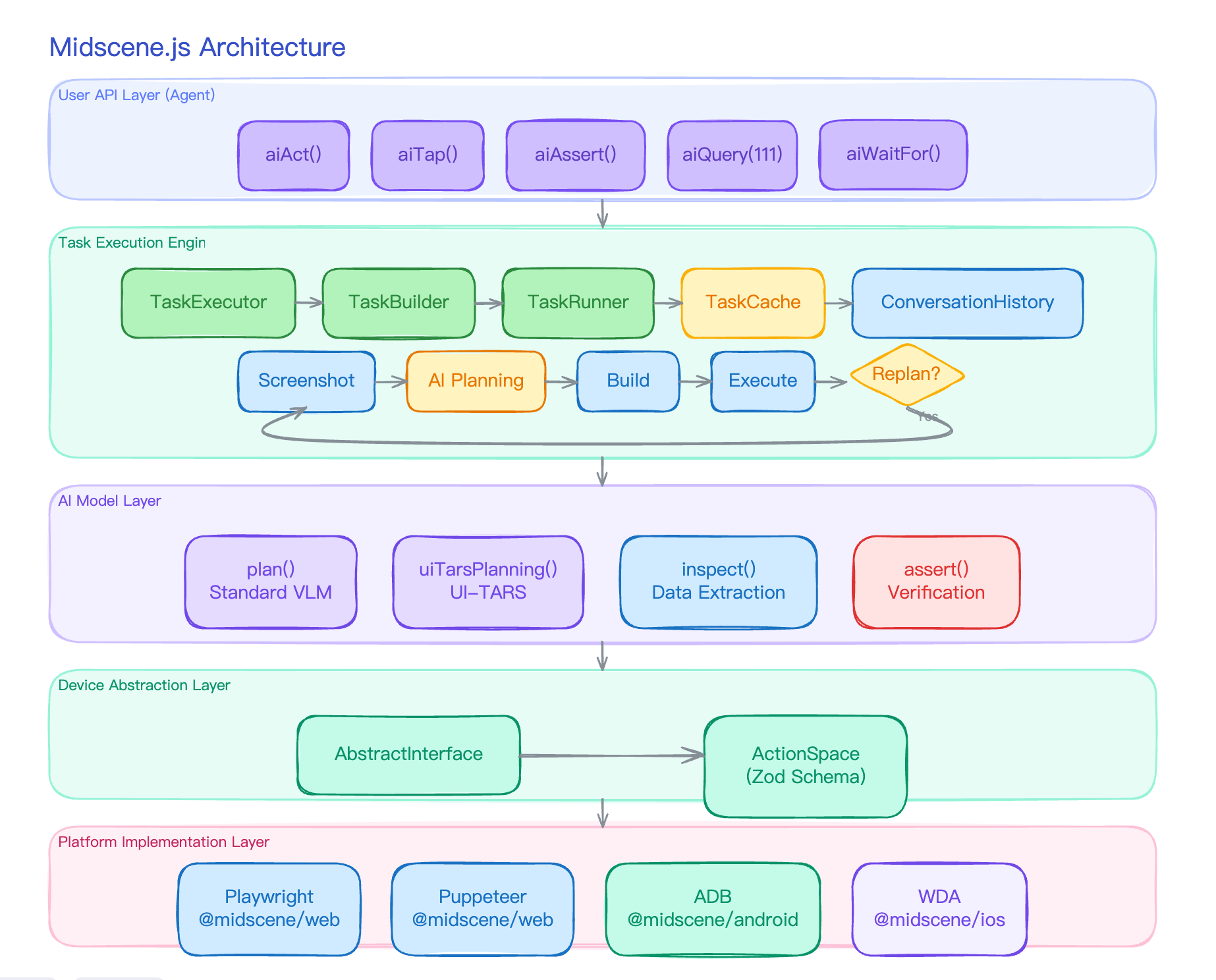
aiAct 不是一次模型调用
很多人第一次看视觉 Agent,会下意识假设它是这样工作的:
1 | 用户说"登录后下单" → 模型一次性输出所有动作 → 程序按顺序执行 → 完事 |
如果界面足够静态,这种”一次规划、批量执行”理论上能跑通。但真实界面不是这样:点登录按钮之后页面会跳,跳完之后才能看到购物车,购物车里有没有商品要看后端状态,弹窗可能挡住主流程,错误提示要等出现才知道要不要重试。
所以 aiAct 内部实际上是一个 plan-act-replan 循环:
1 | ┌─ 截图 ─┐ |
每一轮循环都从一张新截图开始,让 AI 看到上一步操作之后界面变成什么样了,再决定下一步做什么。直到 AI 自己说”我做完了”,或者达到循环次数上限。
下面把这五步逐一拆开。
第一步:拿到一张截图
这一步很朴素,但有个细节值得说:截图不是每次”想要就拿”。
TaskRunner 内部有一个 300ms 的截图缓存。它缓存的是整个 UIContext(截图 + 页面尺寸 + 元素信息),不只是一张 PNG。规则可以概括成一句”读写分离”:
- 要”做事”的任务(规划、定位、点击 / 输入这些)在 300ms 内复用同一帧——刚截过的图,紧接着的定位和动作直接拿来用,不会每个任务都触发一次
page.screenshot()。 - 要”做判断”的任务(
aiQuery、aiAssert、aiWaitFor这类,代码里统一归为Insight类型)强制重新截图——判断必须基于上一步动作之后的最新界面,用旧帧会误判。
判断依据就一行:forceRefresh = task.type === 'Insight'。所以”复用”不是无差别的,它精确地只发生在执行类任务上。
这个缓存机制本身不分平台,但省下的重复截屏在移动端体感最明显:Android 通过 adb shell screencap 拿一张截图就是几百毫秒级开销,要是同一轮里每个子任务都各截一次,整个循环会慢得没法用。Web 端 page.screenshot() 快一些,省掉冗余截屏同样划算。
第二步:让模型规划下一步
拿到截图后,规划模块会把”截图 + 用户原话 + 可用动作列表 + 对话历史”一起发给 VLM,让它返回这一轮该做什么。
返回的不是 JSON,是 XML。一个典型的响应长这样:
1 | <thought>页面右上角有蓝色的"登录"按钮,我需要点击它</thought> |
为什么是 XML 而不是 JSON?这是个看着无聊、却救过无数次静默失败的决定。
先看 VLM 输出 JSON 在野外的样子——模型经常在字符串里塞进没转义的引号、漏闭合,甚至把字段名拼错:
1 | { |
"登录" 那对没转义的引号会让解析器以为字符串在”蓝色的”处就结束了,后面整段跟着全乱;locte 还拼错了字段名。JSON 是”全有或全无”的——一处坏,整轮规划全部作废,而且要等下一轮 AI 发现界面没变化才察觉。
XML 不一样,它是标签包围式的,逐标签提取(extractXMLTag(xml, "thought")):某个标签里塞了什么噪声、缩进乱不乱、引号配不配对,都不影响下一个标签被正确切出来。<thought> 烂了,<action-type> 照样能读。
而且 XML 并没有丢掉结构化数据——action-param-json 这个字段本身是真 JSON,只是被包在 XML 标签里,解析时单独抽出来走 safeParseJson()。即便这段 JSON 坏掉,也只影响这一个动作的参数,不会冲垮整段响应里的 thought、log、memory。
一句话:格式选型不是审美问题,是鲁棒性杠杆——挑那个对”生产者最容易犯的错”最宽容的格式。VLM 爱在自由文本里塞乱字符,就用标签把每个字段隔离开;哪天模型输出严丝合缝了,这个选择也能反过来。
解析完成后,结构会被规范化成一个 PlanningAIResponse,里面有几个关键字段:
actions:这一轮要执行的动作数组(注意 AI 实际返回的是单数action,规范化时统一改成复数)thought、log、memory:思考、日志、记下来的东西(下面讲 ConversationHistory 时会用到)shouldContinuePlanning:这是循环的开关——是不是还要再来一轮
shouldContinuePlanning 怎么决定?看 AI 有没有返回一个 <complete> 标签:
1 | <thought>用户要求的操作已全部完成</thought> |
只要 AI 自己在最后说 “complete”,循环就退出;否则默认继续。整个”什么时候停”的判断权是交给模型的,而不是用规则硬编码。这一点很关键,下面会再提到。
第三步:把规划翻译成可执行的任务
AI 返回的 actions 还不是能直接跑的东西。它长这样:
1 | { type: "Tap", param: { locate: { prompt: "登录按钮", bbox: [...] } } } |
这里有两个不能直接执行的原因:
bbox不够准——这是 AI 在规划时”顺手”给的估算,可能偏几十像素,对小按钮直接信任就会点错。- 不同动作的参数结构差很多——
Tap需要locate,Input需要locate + value + mode,DragAndDrop需要两个locate,AndroidBackButton什么参数都不要。
所以中间会有一个 TaskBuilder,把每个抽象 PlanningAction 拆解成具体的 ExecutionTaskApply[]。以一个简单的 Tap 为例:
1 | Tap{ locate, bbox } → [ LocateTask, TapActionTask ] |
Locate 任务负责把”登录按钮”这个描述变成精确像素坐标,Tap 任务拿到坐标后才真的点。这一步是 Midscene 工程化里最关键的拆分之一,但展开讲会喧宾夺主——下一篇《Midscene 为什么要把 Locate 与 Action 拆成两步?》会单独写。
这里只需要知道:规划之后不会立刻执行,会先经过一次”动作拆解”,把所有需要定位的字段抽出来变成独立的 Locate 任务。
第四步:顺序执行任务
拆完之后是一个扁平数组,TaskRunner 按顺序逐个跑,每个任务有自己的状态机:
1 | pending → running → finished / failed |
任务之间通过一个简单的”上下文传递”机制串起来:Locate 任务执行完会把结果塞进它后面那个 Action 任务的 param.locate 字段(通过 onResult 回调)。所以 Tap 任务执行时拿到的是已经精确化过的坐标,而不是 AI 给的那个粗糙 bbox。
执行失败怎么办?失败也是一种信号——任务会被标记 failed,但循环不一定就停,而是把失败信息塞进对话历史,让下一轮 AI 自己看截图判断要不要重试、换一种打法或者放弃。这又是把决策权交给模型,而不是用 try/catch 硬扛。
第五步:要不要再来一轮
这一步只有一个判断:shouldContinuePlanning === true 就继续,false 就退出。
但这里有一个保险——循环次数上限。不同模型上限不一样:
| 模型类型 | 最大循环次数 |
|---|---|
| 标准 VLM(Qwen、Gemini、GPT-4V) | 20 |
| UI-TARS | 40 |
| AutoGLM | 100 |
为什么标准 VLM 给 20?因为这些模型不是为长链条规划训练的,循环超过 20 轮基本就是它在原地打转。UI-TARS 是字节专门为 GUI 任务训的,规划链更长更稳,所以给 40。AutoGLM 走的是另一套范式(每一轮 AI 决定的粒度更细),所以给 100。
这个上限的本质不是”防止任务执行不完”,而是防止 AI 自己幻觉出无意义的下一步、停不下来。
多轮之间,AI 怎么知道之前发生了什么
到这里整个循环就闭合了。但还有一个问题没回答:第 2 轮规划怎么知道第 1 轮已经做过什么了?
答案是 ConversationHistory——一个属于 TaskExecutor 的对话上下文管理器。它维护五样东西:
messages:LLM 标准格式的对话历史(每轮的截图 + AI 响应都追加进来)memories:AI 自己学到的”我记住了什么”subGoals:deepThink 模式下的子目标列表historicalLogs:非 deepThink 模式下跨轮记录已执行的步骤pendingFeedbackMessage:给下一轮的反馈(上一步成败、错误信息等)
subGoals 和 historicalLogs 是互补的:开了 deepThink 用前者维护”我打算做什么”,否则用后者维护”我做过什么”。
每次 aiAct() 被调用时,ConversationHistory.reset() 会清空所有历史。换句话说,两次独立的 aiAct() 调用之间,上下文是断开的。这是有意为之:每个 aiAct 是一次有边界的任务,而不是一个长开聊天。
但在单次 aiAct() 内部的多轮之间,上下文是累积的——第 2 轮规划时,AI 能看到第 1 轮的截图、自己说过的话、操作结果。
截图太大怎么办
这里有个工程问题:每轮都把截图塞进去,几轮之后 token 就爆了。一张 1280×720 的截图 base64 之后是几十 KB,对应几千 token,五六轮就把上下文窗口塞满了。
Midscene 的处理是 snapshot(maxImages):从消息末尾往前数,只保留最近 N 张截图,更早的截图替换成占位符 (image ignored due to size optimization)。
- 普通模式 N=1,只保留最新这张
- deepThink 模式 N=2,保留最新两张方便 AI 对比”操作之前 vs 操作之后”
外加 compressHistory(50, 20)——消息总数超过 50 时只保留最近 20 条。两层机制叠在一起,循环跑十几轮也不会让 token 失控。
整张图
把上面五步连起来,一次 aiAct("在搜索框输入 Midscene 并点击搜索") 大致是这样跑的:
1 | 轮次 1 |
这个循环骨架是 Midscene 工程化的核心。所有其他特性——缓存、deepThink、deepLocate、模型自由——都是在这个骨架上加的层。
总结
aiAct 不是把整段任务一次扔给模型,而是把”看 → 想 → 做 → 再看”这个人类自然的工作方式翻译成一个程序循环:
- 截图给模型当前界面的真实状态,每轮都重新看
- 规划用 XML 让模型返回下一步动作 + 要不要继续
- 拆分把抽象动作变成”先定位、再执行”两步
- 执行按顺序跑,结果通过回调串起来
- Replan 让模型自己决定什么时候停,再加一个硬上限兜底
- ConversationHistory 把多轮之间的截图和上下文串起来,并通过限制截图数控制 token
下一步该深挖的是循环里最关键的那一站——“找元素”。AI 给的那个 bbox 为什么不够准?四级 Fallback 链是怎么从”免费估算”一路降本提精到”昂贵的精确定位”?这部分放在下一篇 Midscene 为什么要把 Locate 与 Action 拆成两步? 里讲。
Midscene 的一次 aiAct 里到底发生了什么?

